Dynamic Glyph Atlas for Korean Text Rendering
Dynamic Glyph Atlas for Korean Text Rendering
텍스트 렌더링이란 결국 우리가 쓰는 문자를 어떻게 화면 속 텍스트로 옮길 것인가를 다룬다.
이 과정에서 Character(문자)는 glyph(실제로 그려지는 image) 단위로 처리된다는 점이다.
사람이 보는 문자열과 달리 컴퓨터는 코드포인트에 대응되는 고정된 단위로 변환해야 할 필요가 있다.
이를테면 UTF-8을 가변 길이 인코딩이라고 보는데, 8비트 ASCII로는 한국어나 중국어를 표현할 수 없기에
1바이트가 2,3,4바이트와 혼용될 수 있기 때문이다. 따라서 UTF-32 같읕 고정 길이의 코드포인트 배열을
사용하는 게 일반적이다.
코드포인트는 각 문자를 구분하는 일종의 ID 같은 건가 보군, 그럼 이미지는 어디서 만드는데?
이렇게 지정된 코드포인트는 ttf폰트 파일을 통해 해당 character에 대응하는 glyph를 생성할 수 있다.
폰트는 character에 대응하는 외곽선 벡터를 가지고 있고, 이를 기반으로 비트맵을 생성한다. 이 과정에서
단순히 이미지뿐만 아니라 텍스트의 배치를 위한 타이포그래피 메트릭도 계산되는데, 글자 간격이나
정렬처럼 어디에 배치될 지에 대한 정보다.
그러나 매번 모든 character를 새로 생성하는 것은 비효율적인 지라 한번 생성한 glyph는 캐시에 저장해
재사용한다. 이것이 바로 이 문서의 제목에 달린 Glyph Atlas이다. ‘아틀라스’는 하늘을 떠받치는 그리스
신화 속 신이며 그 어원 때문인지 지도책으로, 나중에는 그림 모음집이라는 뜻으로 쓰였다. 알다시피
컴퓨터는 여백에 대해서도 메모리를 할당하며 오늘날 Texture Atlas란 용량을 줄이기 위해 여러 개의 작은
텍스처를 하나의 큰 텍스처 파일로 합쳐놓은 것을 말한다.
Glyph Atlas도 결국 사용하는 문자에 대해 따로 모아둔 캐시라는 거잖아?
그렇다. 새로운 glyph가 필요하면 atlas의 빈 공간에 추가하고, 이미 존재하는 glyph는 다시 생성하지
않고 기존 데이터를 그대로 사용한다. 각 glyph는 위치 정보를 가지고 있기에 가져올 수 있다. 이때
똑같은 크기의 격자로 구분해 가져오는 게 아니며, 가져온 것들은 사각형 형태로 변환되고 렌더링된다.
각 사각형은 자신의 UV 좌표를 이용해 atlas에서 해당 glyph 영역을 샘플링한다. 보통 atlas는 알파
값만 가진 텍스처로 구성되고, 셰이더에서는 이를 마스크처럼 사용해 글자 모양을 만들어낸다.
즉, 화면에는 색이 있는 사각형 위에 glyph의 알파 형태를 입혀 텍스트가 표현된다. 이런 방식으로
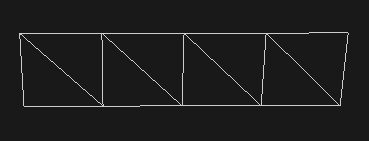
구현되었기에 와이어프레임을 봤을 때 글자들이 빈 사각형으로 나타난다. 아래에 그 경우를 첨부하겠다.\

GitHub 계정으로 댓글을 작성합니다.
현재 추천 수: 조회 중...
GitHub 이슈의 👍 반응을 집계합니다.
추천(👍) 남기기
이 문서 작업실에서 편집하기